Motivación: Aplicaciones de la Regresión en la Investigación#
El análisis de regresión es una poderosa herramienta estadística utilizada en varios campos de investigación para comprender la relación entre variables y realizar predicciones. El análisis de regresión es también la herramienta fundamental de la Econometría, la disciplina en economía que estudia herramientas estadísticas específicas para estudiar fenómenos económicos.
El análisis de regresión es una herramienta poderosa que permite una serie de aplicaciones interesantes en la investigación cuantitativa. En esta sección introductoria revisaremos algunas, incluyendo la extrapolación de datos, la inferencia de relaciones causales y la construcción de modelos predictivos.
Usos de Regresión#
1. Extrapolación y Predicción de Datos:
Una primera aplicación de la regresión es la extrapolación de datos. Permíteme comenzar ilustrando este uso con un caso de estudio que me gusta mucho: cómo se utilizaron los datos de juegos de Xbox para predecir el resultado de las elecciones presidenciales de Estados Unidos de 2012 (Wang, et. al 2015).
Como es posible que sepas, los métodos tradicionales de encuestas, que típicamente se basan en encuestas telefónicas, se fueron volviendo cada vez menos efectivos debido a las tasas de respuesta decrecientes y muestras sesgadas. Las encuestas pueden estar fácilmente sesgadas hacia demografías específicas. Reconociendo este desafío, los investigadores propusieron un enfoque novedoso: aprovechar la vasta base de usuarios de la consola Xbox para lanzar una encuesta y crear un conjunto de datos que reflejara las características demográficas de la población votante real. A primera vista, esto podría sonar extraño: se espera que los usuarios de Xbox también estén sesgados en relación con la población, específicamente hacia personas más jóvenes!
Sin embargo, los investigadores en este caso utilizaron una estrategia ingeniosa para resolver el sesgo. Aprovechando las miles de respuestas que podían obtener de usuarios de la x-box, crearon una cuadrícula de diferentes perfiles demográficos (e.g. grupos de edad, género, etc) para estimar las tendencias de votación de cada grupo basándose en sus características. Cuando los datos para combinaciones específicas de características no estaban disponibles o eran muy pocos, los investigadores utilizaron interpolación, basándose en los resultados de grupos demográficos similares. La regresión jugó un papel crucial en este proceso de interpolación, permitiendo a los investigadores hacer predicciones incluso para los grupos con menos datos. Una vez completa la cuadrícula con las tendencias de votación de cada grupo, los investigadores ponderaron a cada grupo según la participación que tiene cada uno en la población de votantes (este proceso es comúnmente denominado post-estratificación). Como resultado, pudieron obtener predicciones bastante cercanas a las que finalmente ocurrieron.
2. Inferencia de Relaciones Causales:
Más allá de la predicción, la regresión juega un papel crucial en la inferencia de relaciones causales entre variables. Tomemos como ejemplo el estudio de Lagomarsino y Rossi (2024) sobre el impacto de un programa de subsidios a la vivienda en la violencia doméstica contra las mujeres. Este estudio fue diseñado para evaluar si el programa, que utilizaba un sistema de lotería para asignar viviendas, tenía consecuencias no intencionadas en términos de violencia contra las mujeres.
Podríamos pensar que para evaluar el impacto de un programa de este tipo es comparar a los hogares que recibieron subsidios contra los que no lo hicieron. Sin embargo, como veremos en detalle cuando estudiemos inferencia causal más adelante, uno de los principales desafíos de este tipo de comparaciones es la de realizar una comparación de «peras contra manzanas»: probablemente receptores y el grupo de comparación eran diferentes en primer lugar.
En este caso, los investigadores compararon las experiencias de aquellos que recibieron vivienda a través de la lotería con aquellos que no lo hicieron, proporcionando un entorno cuasi-experimental para evaluar el efecto del programa. Utilizando modelos de regresión, estimaron el efecto causal del programa en la violencia doméstica, teniendo en cuenta otros factores que podrían influir en el resultado. Esto demostró el poder de la regresión para evaluar el impacto causal de las intervenciones, particularmente cuando los experimentos controlados son difíciles o no éticos.
Veremos que el método de regresión es particularmente valioso para analizar datos observacionales, donde la asignación aleatoria a grupos de tratamiento y control es imposible. Al controlar cuidadosamente las variables de confusión potenciales a través de la regresión, los investigadores pueden estimar el efecto causal de una intervención o factor particular en una variable de resultado.
3. Construcción de Modelos Predictivos:
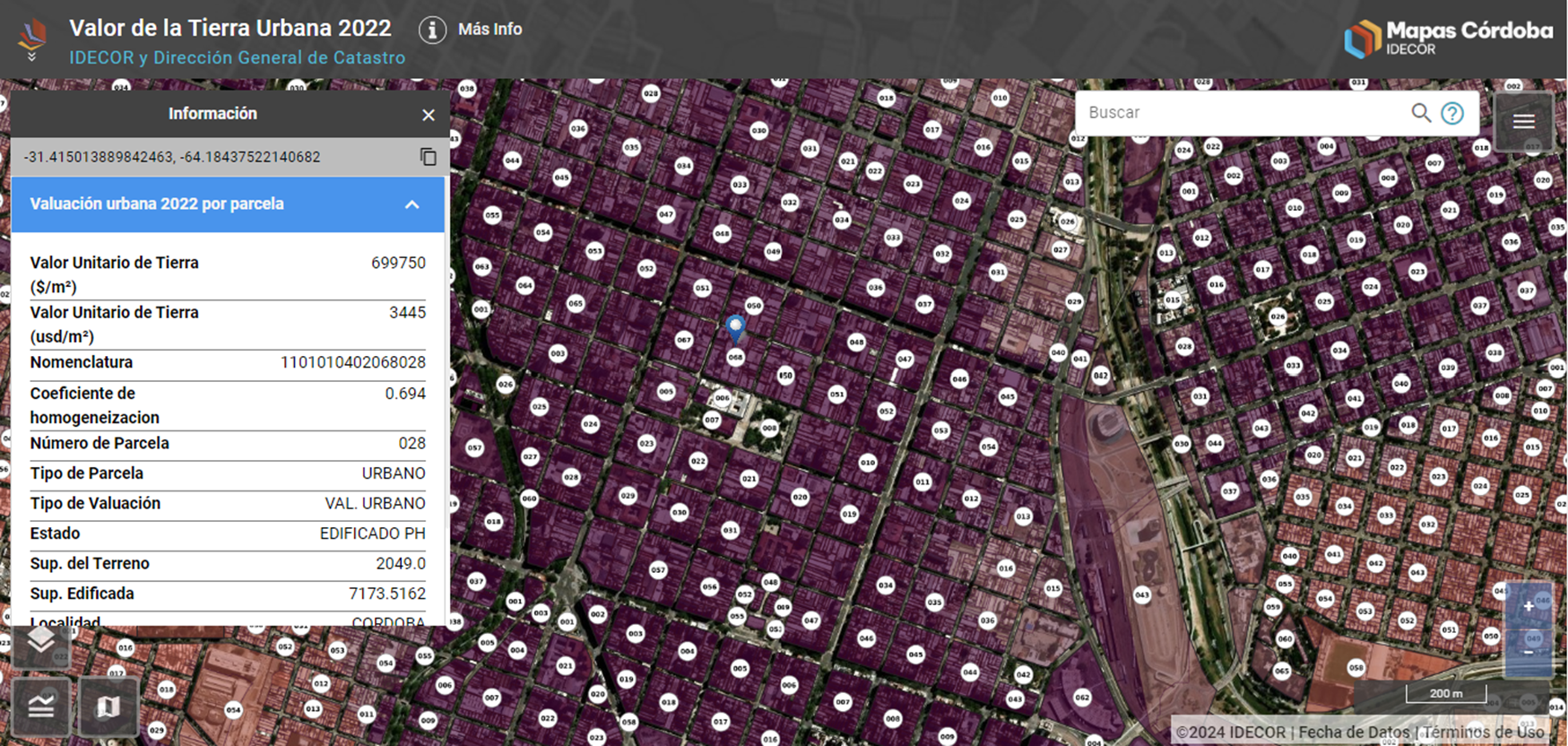
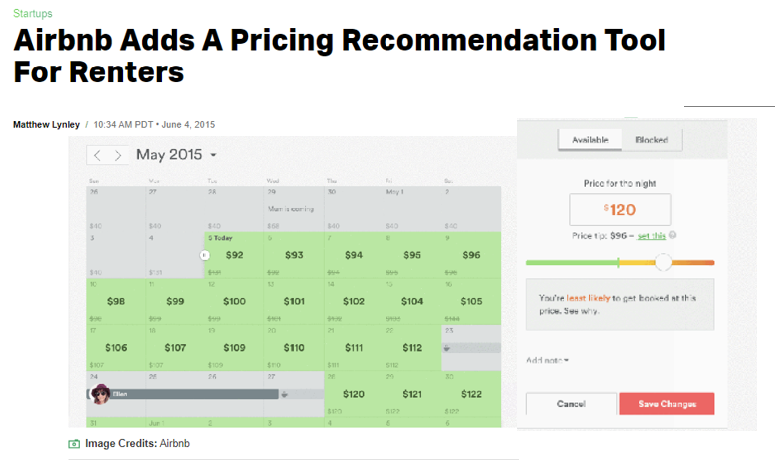
Como tercer caso de uso de los métodos de regresión, podemos mencionar que la regresión se utiliza ampliamente para construir modelos predictivos, permitiendo a los investigadores estimar el valor de una variable «dependiente» basándose en los valores de variables «independientes». Consideren por ejemplo el caso de la valuación del valor de los terrenos que tiene que hacer un municipio para cobrar impuestos. O tal vez las recomendaciones que un sitio como Airbnb hace a los dueños cuando estos quieren fijar el valor de alquiler de sus propiedades. En estos casos se utilizan variantes del «modelo de precios hedónicos», donde se asume que el precio de una propiedad puede descomponer en sus características observables, como tamaño, ubicación, comodidades y regulaciones de construcción. La suposición es que cada una de estas características contribuye al valor total de la propiedad. Al aplicar la regresión, los investigadores pueden estimar la contribución de cada característica al valor total de la propiedad. Esta información puede luego utilizarse para predecir el precio de mercado de las propiedades basándose en sus características específicas.
Si bien, como veremos los modelos de regresión típicamente asumen relaciones lineales entre variables, la regresión puede utilizarse para modelar relaciones no lineales también. Al aplicar transformaciones a las variables, los investigadores pueden capturar relaciones más complejas entre características y valor de la propiedad, mejorando la precisión del modelo.
Estos ejemplos muestran la versatilidad del análisis de regresión. Desde predecir resultados electorales hasta inferir relaciones causales y construir modelos predictivos para valoraciones inmobiliarias, la regresión proporciona un marco robusto para comprender fenómenos complejos y extraer insights valiosos de los datos.
Wang, W.; Rothschild, D.; Goel, S.; Gelman, A. Forecasting Elections with Non-Representative Polls. International Journal of Forecasting 2015, 31 (3), 980–991. https://doi.org/10.1016/j.ijforecast.2014.06.001.
Lagomarsino, B. C.; Rossi, M. A. JUE Insight: The Unintended Effect of Argentina’s Subsidized Homeownership Lottery Program on Intimate Partner Violence. Journal of Urban Economics 2024, 142, 103612. https://doi.org/10.1016/j.jue.2023.103612.